A new study by Kilo AI has revealed a key distinction between flagship models: Claude Fable 5 demonstrates significantly better architectural design capabilities, while GPT-5.5 offers a more efficient and cheaper solution for direct code implementation.
What Happened
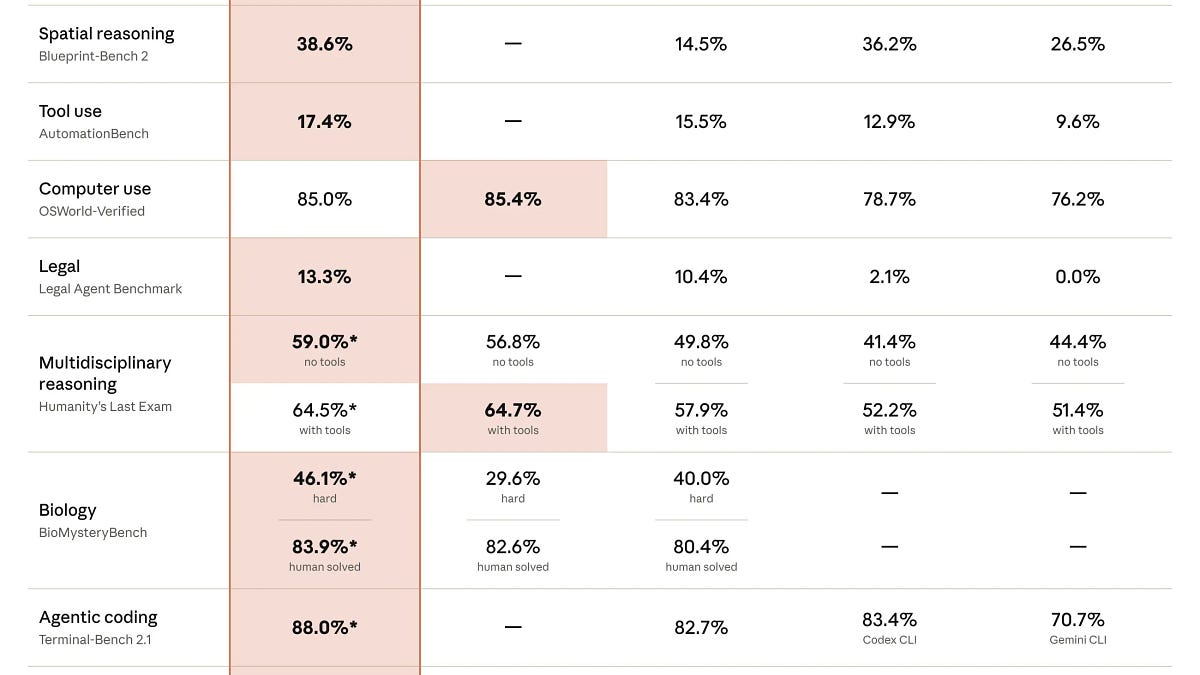
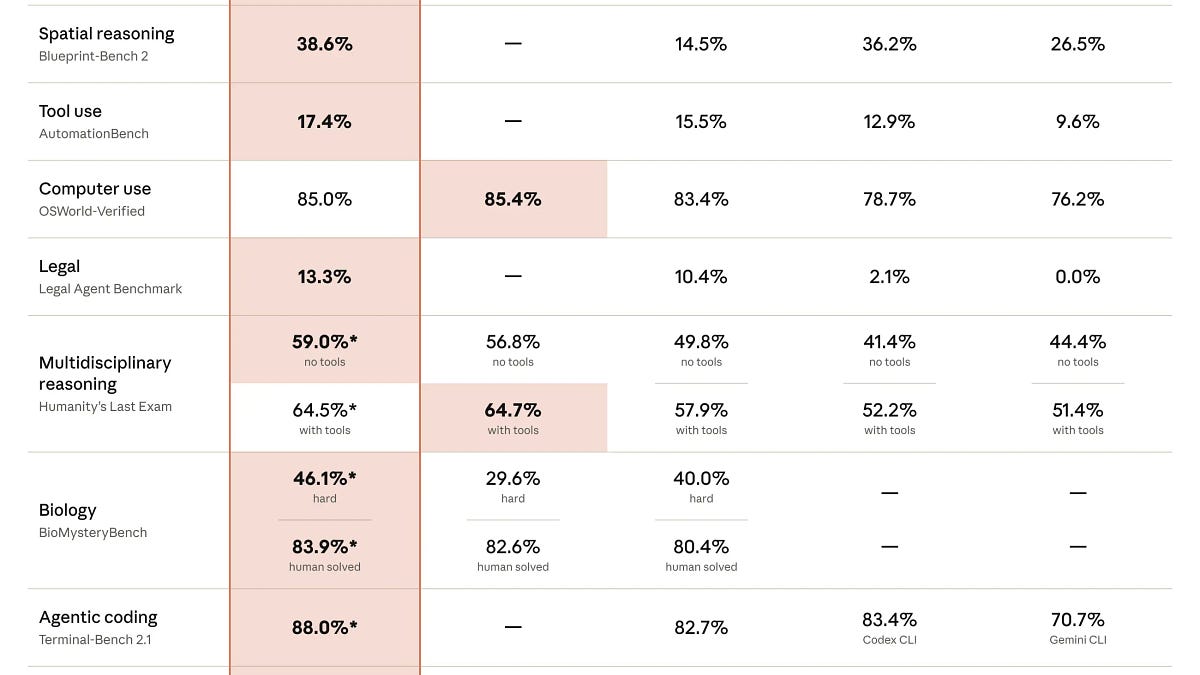
During comparative testing while developing a feature flags service, the Claude Fable 5 model scored 9.1 on the architectural planning scale, outperforming GPT-5.5, which scored 8.3. Meanwhile, both models showed comparable results in the direct execution of written code, but GPT-5.5 proved to be significantly more cost-effective to use.
Context
This study highlights the gap between a model's high-level reasoning capabilities and its efficiency in code generation tasks. The results validate the viability of the Plan-and-Execute strategy, where tasks are divided among specialized agents.
Why It Matters for the Industry
For the industry, this signifies a shift from using a single universal model to creating multi-agent systems and specialized chains. Standardizing Planner-Executor architectures will allow software development pipelines to be optimized by delegating design to the most "reasoning-heavy" models and code writing to more economical flagships.
Why It Matters for Users
Developers and engineering teams can implement a hybrid workflow: use Claude Fable 5 to create a detailed technical plan (e.g., in a plan.md format) and then pass that plan to GPT-5.5 for implementation. This approach can reduce LLM API operational costs by nearly 60% without sacrificing product architecture quality.
Sources
Author
Look at AI, Editorial Team