
Using desktop computers, such as a Mac Studio, as dedicated local servers for LLM workloads allows for the creation of a private and distributed infrastructure accessible from any mobile device.

What Happened
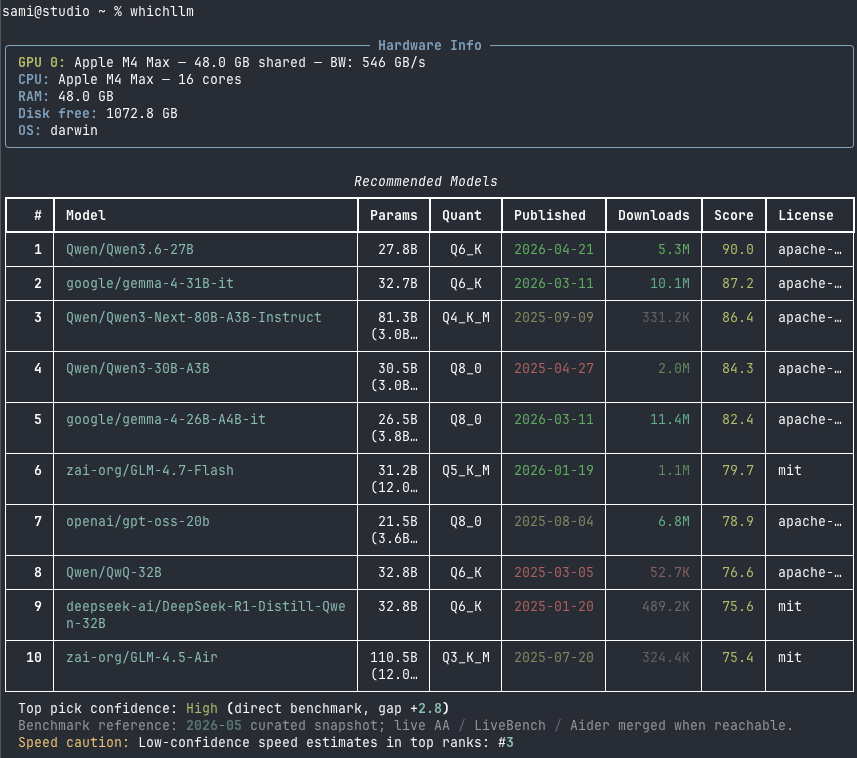
An engineering approach has been proposed for organizing a local AI stack, where powerful desktop hardware acts as a personal API provider. Using Tailscale for network access and LM Studio for model management, heavy LLMs can be run via API without taxing a primary work laptop or mobile device. A key element is the use of fixed model identifiers (e.g., 'studio-llm'), which ensures the stability of client applications even when model weights are updated on the server.
Context
This method is not a scientific breakthrough in LLM architecture, but rather a practical solution for creating 'home clouds' for AI. It relies on existing tools and enables the implementation of a Local-First API concept, where users access high-performance models through a secure and transparent network topology built on Tailscale.
Why It Matters for the Industry
This approach demonstrates a viable model for creating private and distributed infrastructure for local LLMs. It opens possibilities for transitioning from dependence on cloud providers to a hybrid model, where powerful nodes serve as personal API gateways for an ecosystem of less performant Edge-AI devices.
Why It Matters for Users
Users and developers gain the ability to leverage the power of desktop machines for AI tasks on weak devices while maintaining full data privacy. This lowers the barrier to entry for using heavy models on mobile devices and allows small teams to quickly deploy a private testing environment without paying for cloud subscriptions.
What Is Not Yet Known / Limitations
The effectiveness of this solution requires careful analysis of latency and network connection reliability when using remote access.
Sources
Author
Look at AI, Editorial Team